
VLOOKUP関数を使ってリスト作成しているのですが、参照するデータベースの並びが変わると式も修正しないといけなくて面倒です…。
確かに、列追加などがあると参照範囲内の順番も変わるので、VLOOKUP関数の列番号も合わせないとね。
INDEX関数とMATCH関数を使ってみたらどう?
どっちも初耳なのですが…見知らぬ関数を2つも使うくらいなら手作業します。
スプレッドシートやExcelで手作業は絶対にダメ。
それに、これは「データベースの列がずれても指定した項目名を探して抽出できる」画期的な関数よ。
はじめに仕組みを作っておけばメンテナンス不要なので、今ここで覚えてしまいましょう。
- INDEX関数とMATCH関数を理解することで、参照するデータベースの並びが変わっても指定した項目を抽出できる
- VLOOKUP関数やQUERY関数のように都度の数式修正が不要
実務での活用イメージ
例えば、人事担当者の給与計算業務に活用できます。
人事労務ソフトを導入している場合、明細データをCSVファイルでエクスポートして、正しく金額が反映しているかチェックすると思います。
その際、手当項目が増えたり減ったりすると、シート内の列も変わるため、VLOOKUP関数やQUERY関数を使用している場合、その度に数式を変更しなければなりません。
そこで、INDEX関数とMATCH関数を活用すれば、指定した項目名(基本給、通勤手当など)と一致する列を抽出することができます。
私自身、この方法を給与明細の確認作業に取り入れ、あちこちで突合していたものを1つのシート内で完結し、1日掛かっていたところ15分で終えられるようになりました。
反対に、参照するデータベースの並びが変わらない(情報の更新や行が増えるだけ)場合は、このメリットを享受できないため使用する必要はありません。
むしろ、細やかな条件指定ができるQUERY関数の方がおすすめです。(詳しい解説はこちら)
前提:INDEX関数・MATCH関数とは
各関数の特徴は以下の通りです。
- 参照範囲の中で「●行目の▲列目」と住所を特定して、その位置にあるセルの値(文字列や数値)を抽出する
=index(参照範囲,行番号,列番号)
- 検索したい値(文字列や数値)を指定して、参照範囲の中で何行目(or 何列目)にあるか番号を抽出する
- 検索の種類は、完全一致のみを対象にする場合は「0」
=match(検索キー,参照範囲,検索の種類)
これらを組み合わせて使用します。
具体的には、INDEX関数の中で指定する行番号・列番号に、それぞれMATCH関数を適用します。
=index(参照範囲,match(検索キー,参照範囲,検索の種類),match(検索キー,参照範囲,検索の種類))
例えば、人のデータベースであれば「誰(行)」の「何の項目(列)」が必要か、MATCH関数で条件指定します。
そして、MATCH関数によって突き止めた行番号・列番号をINDEX関数に当てはめます。
このようにすれば、もし参照するデータベースの人・項目の順番が変わっても、住所を特定して抽出することができます。
何だかとても便利そうではあるのですが、いきなり知らない関数を2つ組み合わせろと言われてもハードル高いです…。
諦めないで!
「まずはINDEX単体の活用事例を知りたい!」という場合は、こちらの記事でイメージアップしてみてね。
使い方:読売ジャイアンツの例
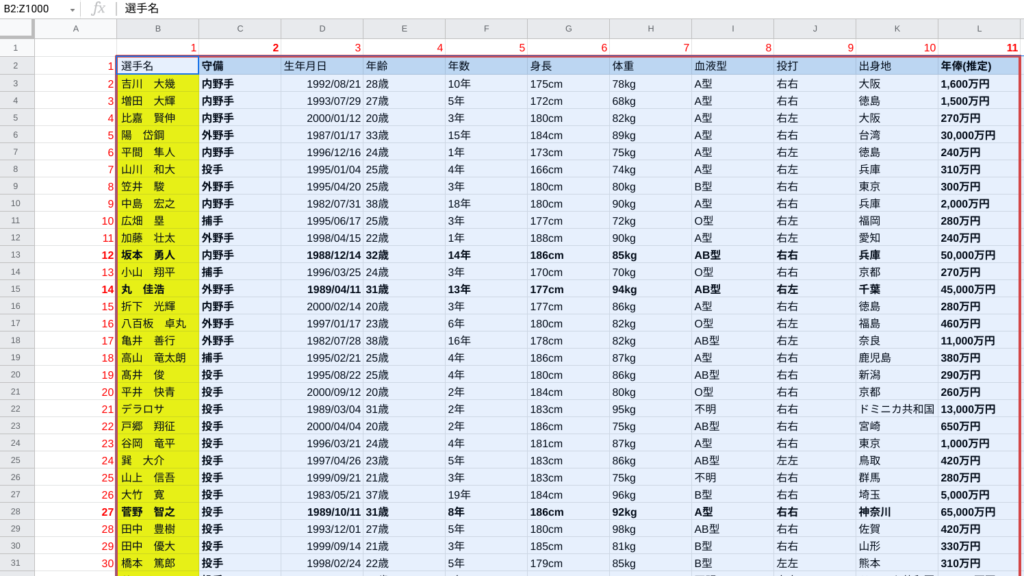
どのように使用するか、読売ジャイアンツを例に見ていきましょう。
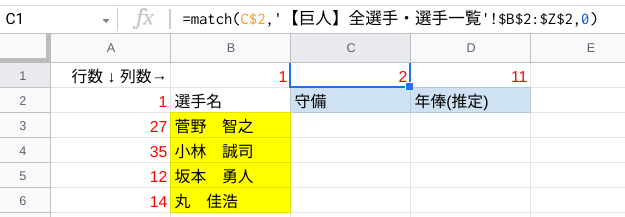
赤枠内が参照するデータベース、黄色セルが対象の人、青色セルが対象の項目になります。
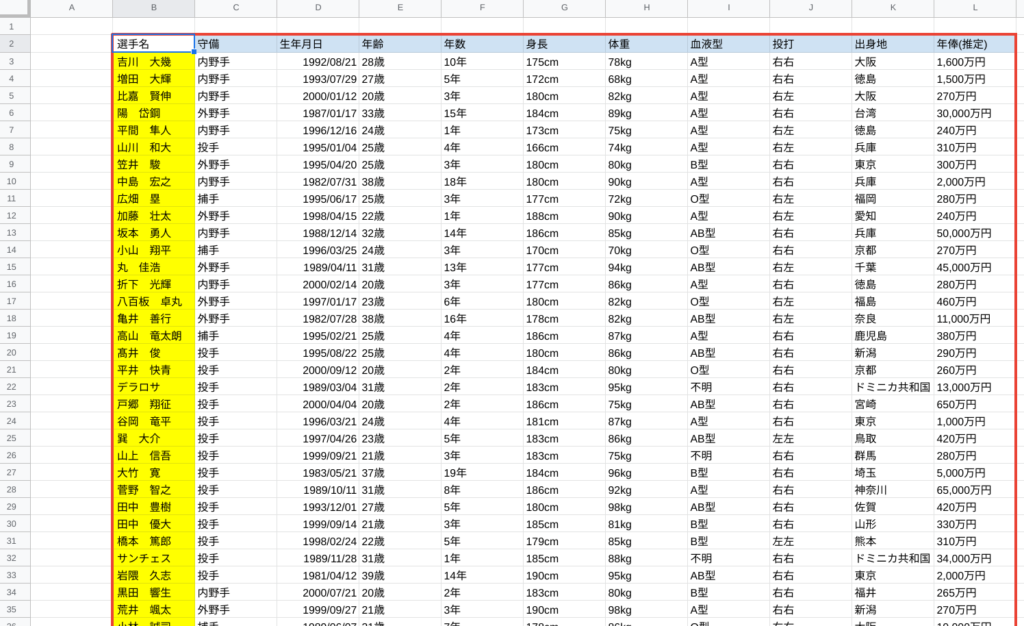
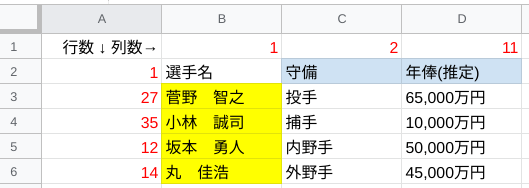
このデータベースから、「菅野 智之」「小林 誠司」「坂本 勇人」「丸 佳浩」の「守備」「年俸(推定)」を抽出してみましょう。
まずは以下の完成形をイメージして下さい。
待て待て。
みんな項目(列)を固定したいワケで、人(行)は固定せずそのままでいいんじゃないか?
(うるさいジジイね)おっしゃる通り、行はそのまま表示させる使い方が多いと思うわ。
まずは関数の仕組みを理解してもらうためにこの順番で説明しているけど、「行はそのままで、項目だけ必要なものに絞りたい」という人は、こちらのチャプターまでスキップしてOKよ。
MATCH関数:必要なデータの行番号・列番号を特定
繰り返しにはなりますが、INDEX関数で必要なデータを抽出するために「何行目の何列目を取ってきてくれ!」と指示をします。
本来はVLOOKUP関数のように、数式内に番号を入力するのですが、今回の目的は「自動抽出(指示を自動化)」なので、この部分にMATCH関数を当てはめます。
行番号を特定:誰のデータが必要か
はじめに抽出対象となる選手名を縦に並べます。
つまり「今、誰のデータが欲しいのか」ということですよね?
そうそう。
但し、一致するセルをデータベースから検索する仕組みなので、コピペ等で正確に入力してね。
続いて、選手名の左にMATCH関数を入れていきます。
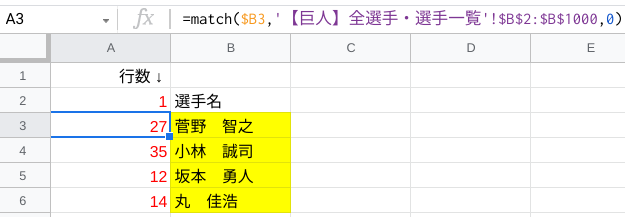
参照範囲はデータベースのB2:B1000(赤枠の最左列)で、その中で何行目に位置しているか番号を表示しています。
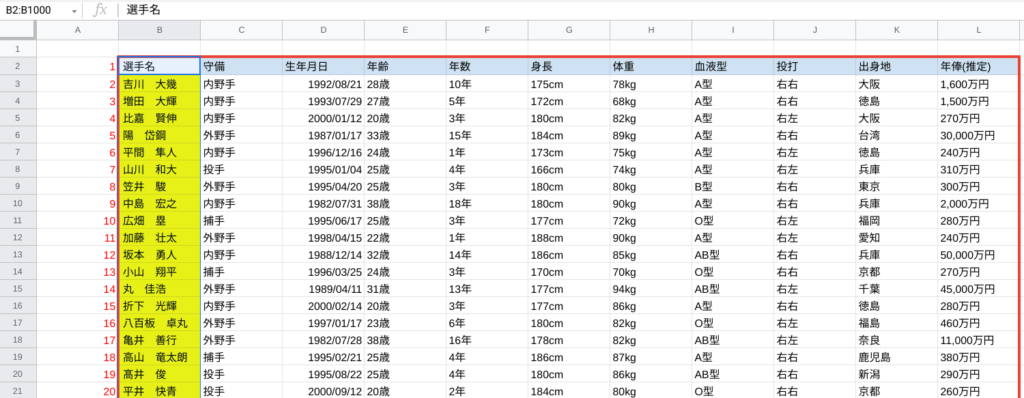
B2:B1000って、1000行目まで範囲指定してるってことですよね?
何か意味あるんですか?
エラーを未然防止するためね。
今後どんどん人が追加されていって、範囲からはみ出てしまうと、参照できずエラーになってしまうでしょ?
自動抽出がメリットなのにいちいち気にしていたら本末転倒なので、「ここまではいかないはず」という広めの範囲で指定するのをオススメするわ。
以下の文字列をコピーして、早速使ってみましょう。(緑文字を置き換え)
=match($B3,'シート名'!$B$2:$B$1000,0)
- 対象者の左にMATCH関数を入力し、それぞれの番号を表示
- 参照先はデータベースの最左列(その中で何行目に位置しているか)
- 貼り付けたいセルにカーソルを合わせて「fx」欄に貼り付け
- キーボード「F2」ボタン(セル編集)を押してから貼り付けでも可
列番号を特定:何のデータが必要か
選手名と同様に、抽出対象となる項目名を横に並べます。
続いて、項目名の上にMATCH関数を入れていきます。
参照範囲はデータベースのB2:Z2(赤枠の最上行)で、その中で何列目に位置しているか番号を表示しています。
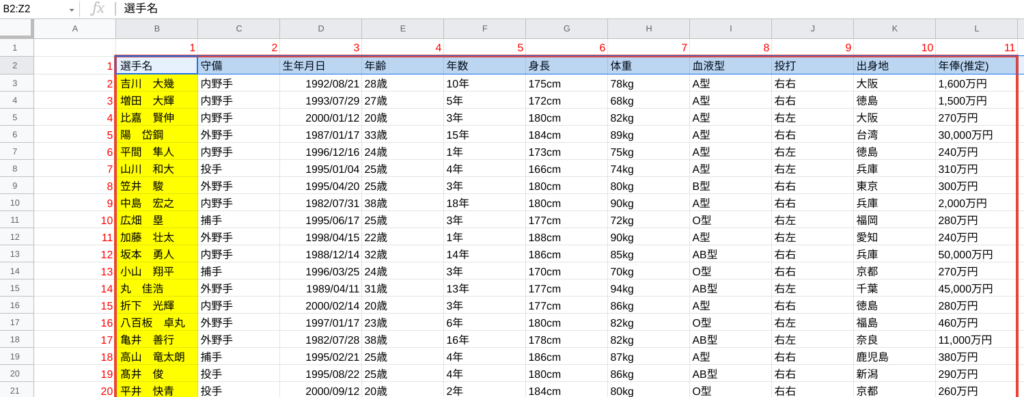
B2:Z2ということは、B列からZ列までの2行目という意味ですよね?
あまり行だけ指定するケースがないので違和感…。
データベースのラベルを指定するイメージかしら。
こちらも参照範囲は広めに取っておきましょう。
=match(C$2,'シート名'!$B$2:$Z$2,0)
- 項目の上にMATCH関数を入力し、それぞれの番号を表示
- 参照先はデータベースの最上行(その中で何列目に位置しているか)
INDEX関数:●行目・●列目に位置するセルを抽出
いよいよ仕上げに入ります。
必要なデータの行番号・列番号を表示できたので、あとはINDEX関数に適用します。
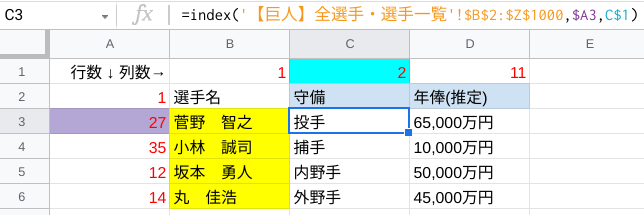
初めての方に向けて、MATCH関数を入力したA3・C1をそれぞれセル参照する方法で数式を作成すると、以下のようになります。
慣れてきたら、INDEX関数の中に直接MATCH関数を入力すると、シートの見栄えもスッキリします。

参照範囲はデータベースのB2:Z1000(赤枠)で、その中で●行目・●列目に位置するセルの値を表示しています。
先ほどMATCH関数で指定したものと同じ範囲ですかね?
まさに、「その範囲内で何番目」という定義がINDEX関数とMATCH関数でずれてしまうと正しく抽出できないの。
コツは、今回でいうB2セルのように始点を定めるとともに、この赤枠のようにデータベースの範囲をイメージすること。
=index('シート名'!$B$2:$Z$1000,match($B3,'シート名'!$B$2:$B$1000,0),match(C$2,'シート名'!$B$2:$Z$2,0))
- INDEX関数の行番号・列番号に、MATCH関数をそれぞれ挿入する
- INDEX関数とMATCH関数の参照範囲を合わせる
- 「その範囲内で何番目」という定義がずれてしまうと、正しく抽出できない
- 今回でいうB2セルのように始点を定めるとともに、この赤枠のようにデータベースの範囲をイメージする
おすすめ活用法:項目だけをカスタム抽出
人事など管理部門では、参照先データベースのうち「行はそのままで、項目だけ必要なものに絞りたい」というケースが多いかと思います。
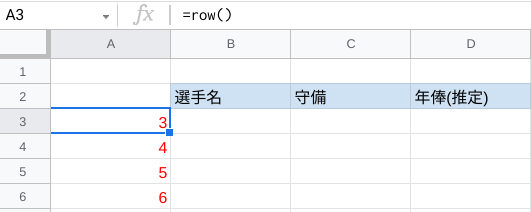
その場合、セルの行番号を表示するROW関数が役立ちます。
例えば、A3セルに「=row()」と入力した場合、「3」と表示されます。
それは、A3セルがシート内で3行目に位置するためです。
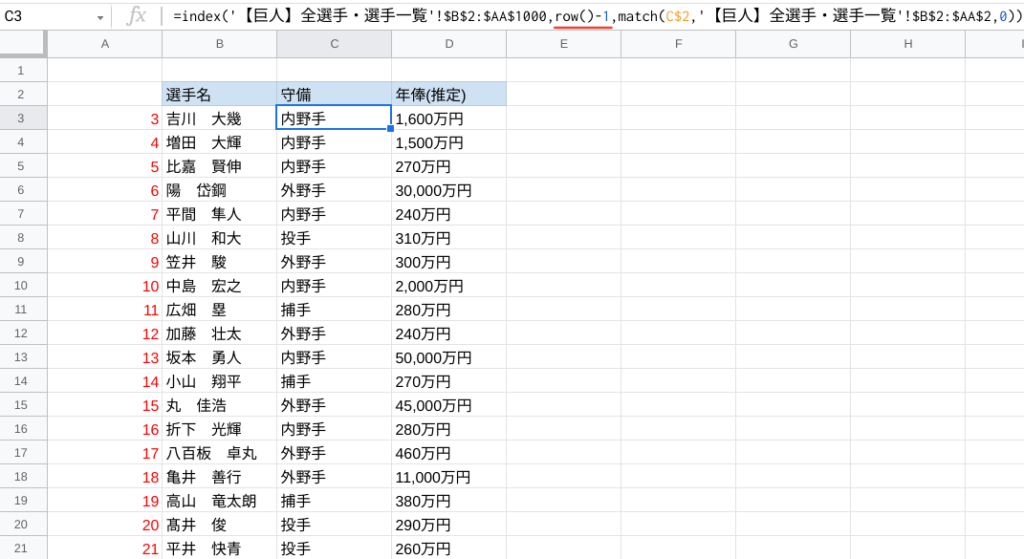
この自動採番機能を活用し、先ほどのINDEX関数の行番号にROW関数を挿入すると、以下のようになります。
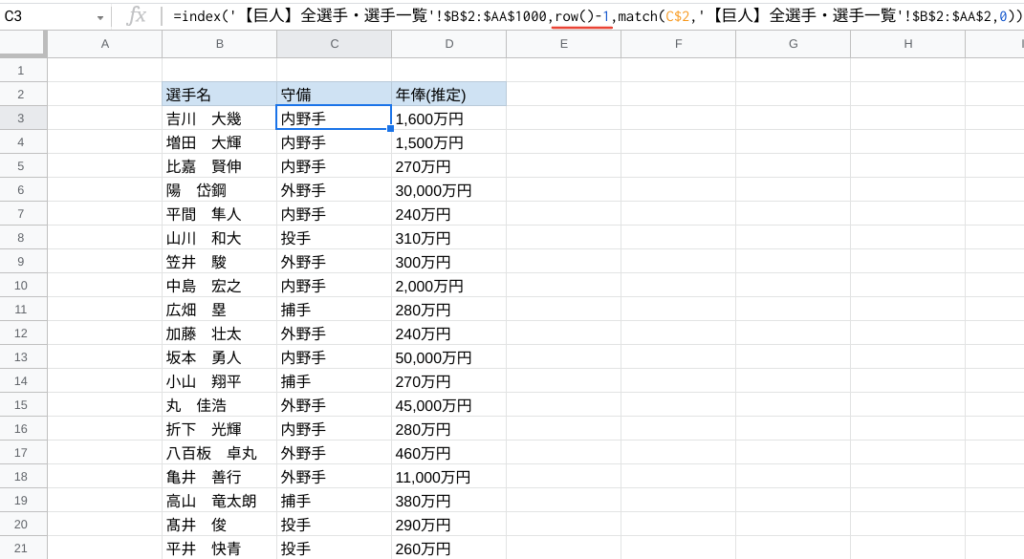
ん?マイナス1ってなんですか?
あ〜、ここはややこしいポイントなので押さえてね。
INDEX関数に入力する行番号は「参照先データベースで何番目か」ということよね?
でもrow()で求められる行番号は「そのセルが作業シートで何番目か」ということなので、一致するとは限らないの。
詳しく見ていきましょう。
参照先データベースではじめに登場する「吉川 大幾」は2行目です。(参照範囲がB2スタートのため)
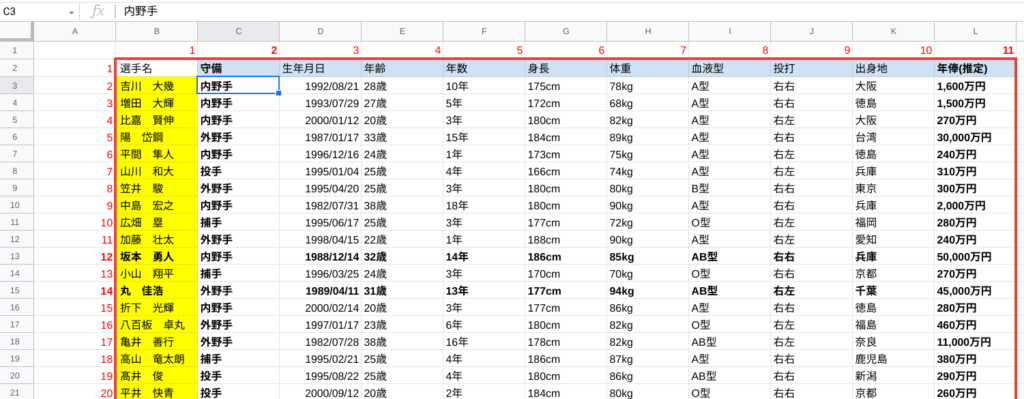
作業シートで「吉川 大幾」を表示させたいのは3行目(row()で求められる番号)なので、INDEX関数に入力する行番号は常にrow()-1である必要があります。
なるほど、理解できました!
あとは下まで数式を伸ばすだけ…僕でも使えそうです!
数式がちゃんと伸びていれば、参照先に新しく追加された人も含めてデータ抽出できるので、是非活用してみてね。
=index('シート名'!$B$2:$Z$1000,row()-1,match(C$2,'シート名'!$B$2:$Z$2,0))
- 「行はそのままで、項目だけ必要なものに絞りたい」ケースでは、ROW関数の自動採番機能を活用する
- INDEX関数の行番号にROW関数を挿入する
- 抽出したいセルが「参照先データベースで何番目か」確認し、差分をROW関数に±(加減算)する
以上、INDEX関数とMATCH関数の使い方について解説しました。
VLOOKUP関数の数式を都度修正したり、手作業で切り貼りしている方は、今すぐ自動化しましょう。
また、こちらの記事では人事担当者向けに従業員情報の管理方法についてシェアしているので、あわせてご覧下さい。

